
GraphRAG: RAG using Graph Database!
RAG, Deeplearning, Graph DB, Neo4J


I am pleased to announce that I have finished yet another interesting short course from DeepLearning.AI and Neo4j - “Knowledge Graphs for RAG”.
This course provided a comprehensive overview of the latest techniques and best practices for building and deploying Graph RAG models for a variety of applications.
Explore advanced techniques for connecting multiple knowledge graphs and using complex queries for comprehensive data retrieval.
Write advanced Cypher queries to retrieve relevant information from the graph and format it for inclusion in your prompt to an LLM.
After course completion, you’ll be well-equipped to use knowledge graphs to uncover deeper insights in your data, and enhance the performance of LLMs with structured, relevant context.
What is RAG Model Architecture?
I have asked the LLM to explain about RAG model architecture. Please find the prompt to Mixtral model in groq and the response. It was an interesting analogy to explain RAG Model Architecture and helps to remember and explain easily.

You are AI engineer, explain as if you explain to your 5 year old about RAG model architecture. Cite some interesting articles to learn more about RAG
Think of it like this: imagine you have a huge library of books, and you want to write a story that includes information from those books. A RAG model is like a helpful librarian who can quickly search through all the books and find the most relevant information for you. Then, you can use that information to write your story.
The RAG model has two main parts: the retriever and the generator. The retriever is like the librarian I mentioned earlier. It searches through the dataset of text and finds the most relevant information for a given prompt. The generator is the part of the model that actually generates the text. It takes the information that the retriever found and uses it to create new sentences.
Using Model: Mixtral-8x7b-32768 on groq
Retriever - A plug & play approach supporting different platforms:
Basically the retriever is searching for the relevant information from the database, the database could be Relational or Vector or Graph Database. I am sure one have advantages over other depending on the scalability.
In Langchain, a retriever is a component that is responsible for retrieving relevant documents or data from a given source, such as a database, a search engine, or a file system. The retriever takes a query as input and returns a set of relevant documents or data that can be used to generate a response to the query.
Vector Databases to the rescue:
Relational world is feeling the heat as usual to adopt to these evolving use cases by building additional features. I remember few years back with the evolution of NoSQL databases like DynamoDB, MongoDB, Couchbase etc, Relational databases implemented the support for json column types. Postgres is ahead [thanks to open source community], you could use postgres as your vector database today using pgvector extension.
pgvector is an extension for the PostgreSQL relational database that adds support for vector embeddings. It allows you to store and manage vector embeddings in a PostgreSQL database, and provides vector search capabilities using the similarity distance between vectors.
While it is possible to store vector embeddings in a relational database, it may not be the most efficient or scalable solution. Specialized databases and tools are available for managing vector embeddings and may be a better choice for large-scale applications.
When it comes to implementing RAG, vector databases are considered one of the top contenders. The most crucial element of vector databases lies in vector search for retrieving reliable information from your database.
Here is interesting explanation of how vector databases work from Ne04j blog.
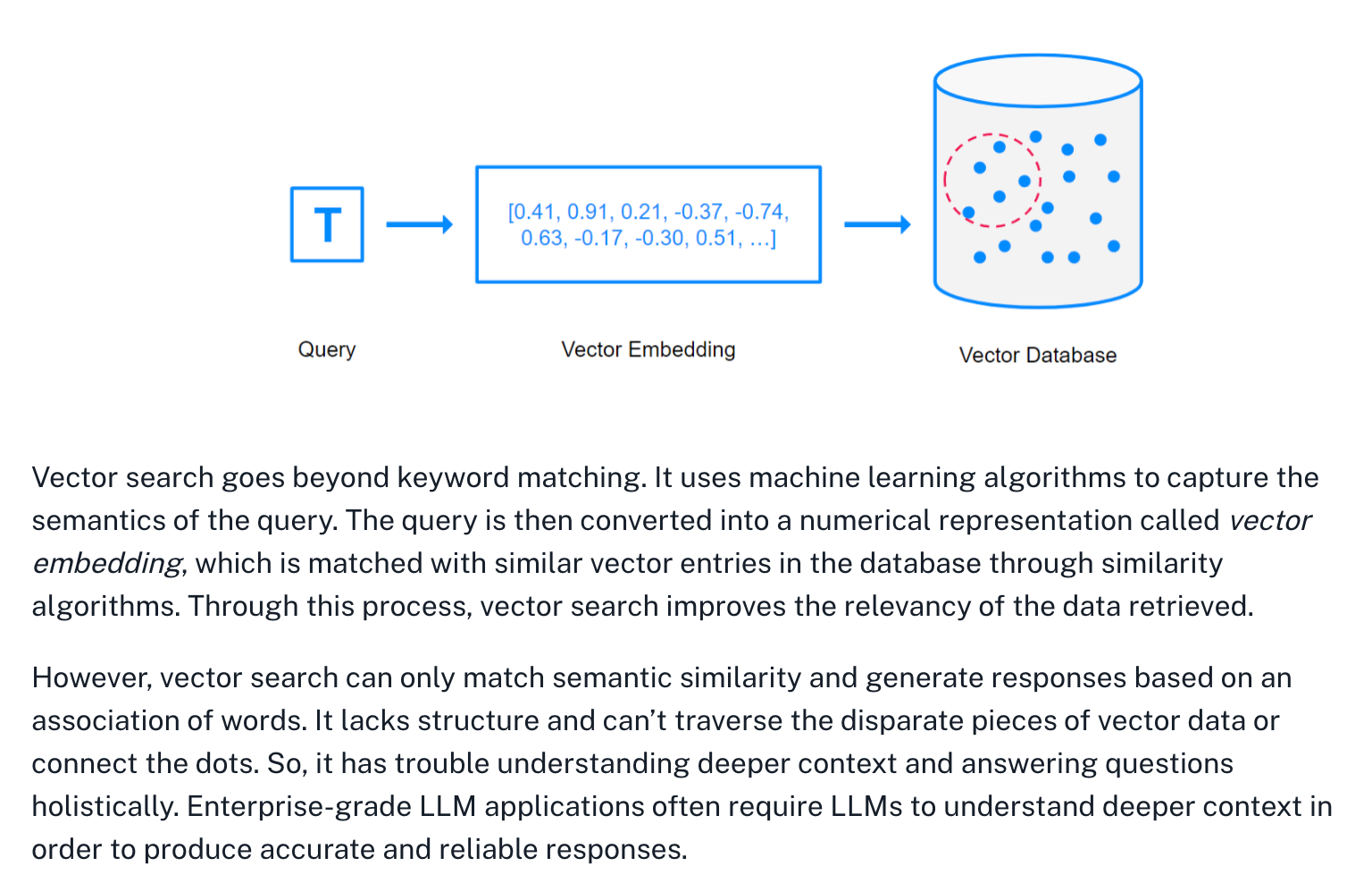
Adding additional context to RAG using Graph Databases:
This course shows interesting demo of combining vector search with Graph search (linked nodes and relationships) as input to LLM to enhance the response.

While vector search is great at matching semantic similarity, it lacks the context, structure, and reasoning required to give meaningful, holistic responses.
Microsoft Research found that using knowledge graphs along with vector search for RAG, an approach known as GraphRAG, greatly extends and enhances its capabilities.
Few Shot learning prompt to generate Cypher query [Writing Cypher with an LLM] for the provided question as an awesome demo.
Glossary:
Neo4J - Graph Database platform
Cypher that allows you to easily query and manipulate graph data
LangChain is an open source orchestration framework for the development of applications using large language models (LLMs). Available in both Python- and Javascript-based libraries, LangChain’s tools and APIs simplify the process of building LLM-driven applications like chatbots and virtual agents.
Related Courses:
I feel the following are other related DeepLearning short courses related to this course and I finished some of them which helped me understand different ways of implementing RAG applications.
Building Applications with Vector Databases [Pinecone]
References: